Kafka : Kafka Streams에 관하여
1. Kafka Streams 개요
Kafka Streams는 토픽에 적재된 데이터를 상태기반(Stateful) 또는 비상태기반(Stateless)으로 실시간 변환 및 토픽에 적재하는 라이브러리.
카프카의 스트림 데이터 처리를 위해 아파치 스파크(Apache Spark), 아파치 플링크(Apache Flink), 아파치 스톰(Apache Storm), 플루언트디(Fluentd)와 같은 다양한 오픈소스 애플리케이션 존재.
Kafka Streams는 카프카에서 공식적으로 지원.
2. Kafka Streams 애플리케이션의 Task와 Partition
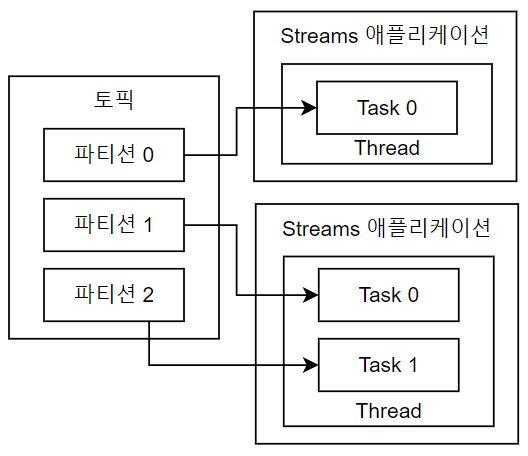
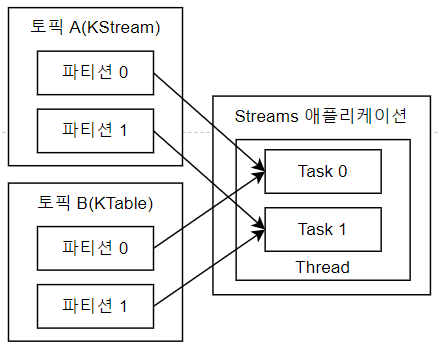
Streams 애플리케이션은 내부적으로 스레드를 1개 이상 생성하며, 스레드는 1개 이상의 Task를 갖음.
Streams 의 Task는 Streams 애플리케이션을 실행하면 생성되며 데이터 처리 최소 단위.
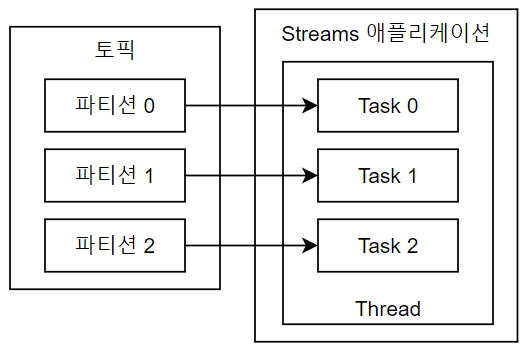
3개의 파티션으로 구성된 토픽을 처리함에 있어 Streams 애플리케이션은 내부적으로 3개의 Task를 갖음.
3. Kafka Streams Topology
Topology 란 2개 이상의 노드들과 선의 조합.
Topology 는 링형, 트리형, 성형 등이 있음.
Kafka Streams 에서는 Topology를 구성하는 노드 하나를 “프로세서(processor)” 라고 함.
Kafka Streams 에서는 Topology를 구성하는 선 하나를 “스트림(stream)” 이라고 함.
4. Kafka Streams Processor
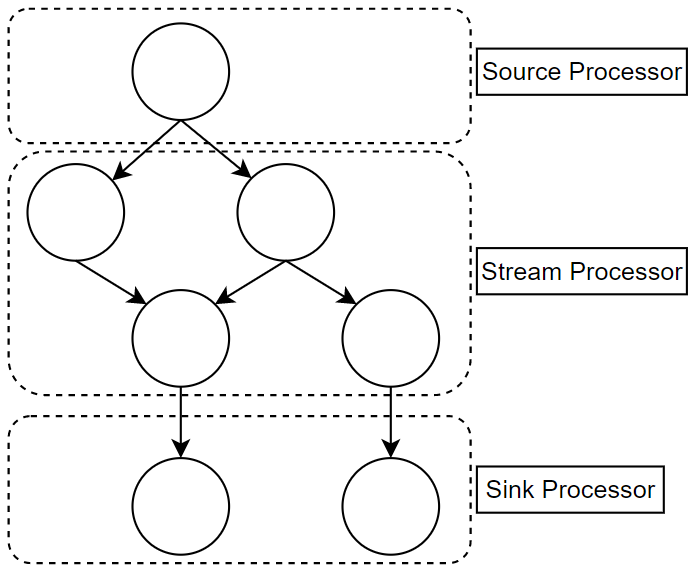
| 종류 | 설명 |
|---|---|
| Source Processor | 데이터를 처리하기 위해 최초 노드, 하나 이상의 토피에서 데이터를 가져오는 역할 |
| Stream Processor | 다른 Processor가 반환한 데이터를 철하는 역할. 변환, 분기처리와 같은 로직 등을 수행 |
| Sink Processor | 데이터를 특정 카프카 토픽으로 저장하는 역할 |
Kafka Streams 개발은 Kafka Streams DSL (Domain Specific Language)과 Kafka Processor API를 활용한 2가지 방법이 있음.
5. Kafka Streams DSL (Domain Specific Language)
Kafka Streams DSL은 레코드의 흐름을 추상화한 KStream, KTable, GlobalKTable 3가지가 있음.
- KStream
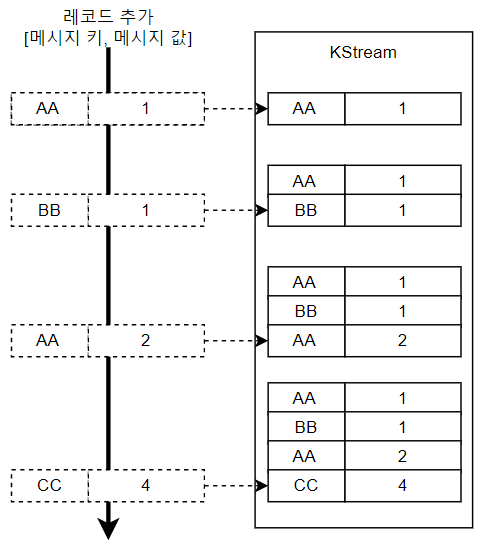
KStream 은 레코드의 흐름.
KStream 을 통해 데이터 조회 시, 토픽에 존재하는 모든 레코드 출력.
컨슈머로 토픽을 구독하는 것과 동일.
- KTable
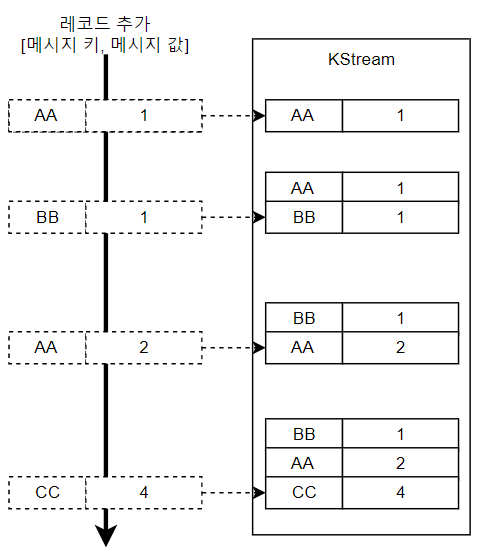
메세지 키를 기준으로 묶어서 활용.
토픽의 모든 레코드를 조회할 수 있는 KStream과는 다르게 유니크한 메세지 키를 통해 가장 최신 레코드를 사용.
파티션 1개와 대응하여 해당 파티션에 대한 데이터로 채워짐.
- GlobalKTable
KTable과 동일하게 메세지 키를 기준으로 묶어서 사용.
KTable과 다르게 모든 파티션에 대응하여 데이터가 채워짐.
6. Kafka Streams & KTable, GlobalKTable
- Streams 와 KTable 조인
KStream 와 KTable를 조인하려면 반드시 코파티셔닝(Co-partitioning)되어야 함.
코파티셔닝(Co-partitioning)이란 조인을 하는 2개의 데이터 파티션 개수가 동일하고 파티셔닝 전략(partitioning stretegy)을 동일하게 맞추는 작업.
KStream과 KTable의 메세지 키가 동일한 경우 조인을 수행.
조인를 수행하려는 토픽들에 대해 코파티셔닝(Co-partitioning)을 보장할 수 없음.
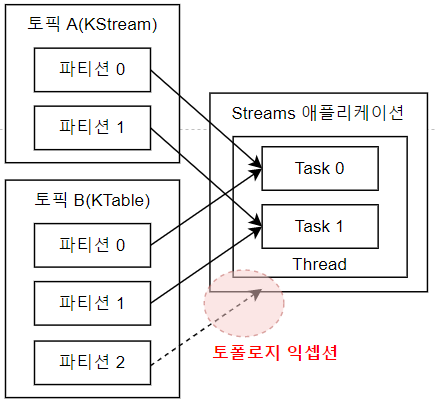
이런 경우 조인을 수행할 수 없음(코파티셔닝이 되지 않은 2개의 토픽을 조인하는 로직 수행시 TopologyException 발생).
조인 수행을 위해서는 리파티셔닝(repartitioning) 과정이 필요.
- Streams 와 GlobalKTable 조인
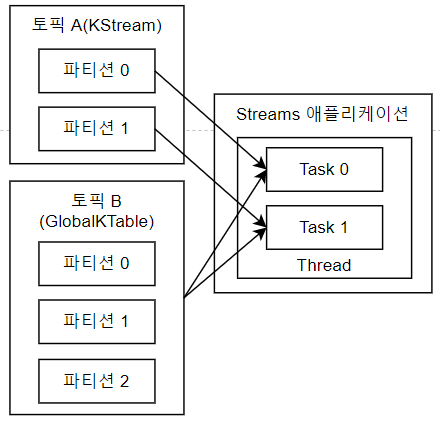
GlobalKTable은 코파티셔닝되지 않은 Kstream과 데이터 조인 가능.
GlobalKTable은 Stream의 모든 Task에게 동일하게 공유가 가능.
모든 데이터를 저장하고 사용하기 때문에 로컬 스토리지 사용량이 증가, 네트워크, 브로커 부하가 클 수 있음.
많은 양의 데이터를 가진 토픽에 대한 조인은 리파티셔닝을 통해 KTable을 사용을 권장.